Normality
If you read Frequentist Statistics: Basics I, we left off on the assumption of standard deviation. If the normal distribution assumption is broken then standard deviation becomes uninterpreted and not very useful to us anymore. When our data doesn’t meet this assumption, we call it skewed or has bad Kurtis.
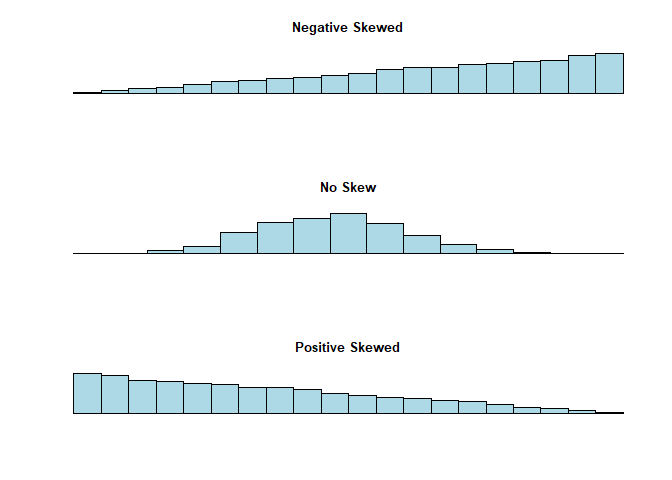
Skewness
There are two types of skewness, positive and negative. If the data is skewed, there are ways to correct for this.. Let me clarify that skewness is how off centered your data is, i.e. how symmetrical your data is. How do you check for skewness? You can simply look at the distribution of your data and check for normality that way. You can also measure it using the formula:
$$Skewness = \frac{\sum_{i=1}^N(X_i - \overline{X})^3} {(N-1) * \sigma^3}$$
Let’s break down the formula - it’s the ith observation minus the mean cubed. Divided by the number of observations minus one multiplied by the standard deviation cubed. You can calculate skewness in R by doing:
#install.packages("moments") - install if needed
library(moments)
data(iris) #load example data
skewness(iris[,1:4])
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 0.3117531 0.3157671 -0.2721277 -0.1019342
How can these values be interpreted? There’s five rules of thumb:
- Skewness between -0.5 and 0.5 is considered symmetrical
- Skewness between -1 and -0.5 is moderately negatively skewed
- Skewness between 0.5 and 1 is moderately positively skewed
- Skewness less than -1 is highly negatively skewed
- Skewness more than 1 is highly positively skewed
So all of sepal metrics we can interpret as symmetrical. Take this with a grain of salt because your sample might not be representative of the population, which is often the case for human data that I work with (see below).
Kurtosis
Kurtosis is how peaky your distribution is. There are three types:
- Platykurtic: The peak is shorter and the distribution is more flat
- Mesokurtic: The peak is similar to a normal distribution
- Leptokurtic: The peak is taller and the distribution is more pointed
The equation is:
$$kurtosis = \frac{\sum_{i=1}^N(X_i - \overline{X})^4}{N * \sigma}$$
Let’s break down the formula - it’s the ith observation minus the mean to the fourth power. Divided by the number of observations multiplied by the standard deviation. You can calculate kurtosis in R by doing:
kurtosis(iris[,1:4]) #from the moments package
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 2.426432 3.180976 1.604464 1.663933
How can these values be interpreted?
- Kurtosis < 3 is platykurtic
- Kurtosis = 3 is mesokurtic
- Kurtosis > 3 is leptokurtic
How much leniency is allowed? It doesn’t seem exactly clear so I’m going to link to a stack exchange conversation.
Sampling
Is normality a big deal? Yes and no. In today’s times, datasets are much bigger than they used to be. Due to the central limit theorem larger datasets automatically move towards normality. Through lots of simulations done by smart people, generally any random sample > 30 will be okay. The issue I have, is in practice no one is ever randomly sampling for the population they are describing. For example if I’m interested in how many words can the average human remember in 10 seconds and my sample only consists of psychology college students, my sample isn’t exactly randomly sampled. This is a problem in a lot of studies and isn’t only a problem when sampling from college students. This sampling problem isn’t only related to the central limit theorem, it also pertains to the generalization of your findings.
In the next post I’ll discuss the null and alternative hypotheses, some opinions on problems with how frequentist statistics are used.